The creation of these components leveraged international best practices, recognized environmental data models and open (web, biodata and geospatial) standards but also cutting-edge technical approaches. Towards the end of the research programme, the lessons from the research that was undertaken and associated technical engagement with international peers were used to create a proof of concept for a multi-indicator environmental data infrastructure.
The IDA Linked Data Registry helps integrating environmental datasets in a standardised way. It uses Semantic Web standards and technology to store, organise, search, and publish classification data on the web. This proved to be convenient, light-weight ontology for describing and organising the land-use classes, soil vocabularies, and property definitions, and was well received as a useful tool to end-users.
The IDA programme also investigated storage infrastructures, such as data cube technologies. Data cubes can be defined simply as multi-dimensional arrays, typically holding large amounts of data such as sequences of satellite images or model output for a series of time steps, though single snapshots (or iterations of snapshots) of non-temporal data can also be stored. Within IDA, a team of scientists evaluated readily available data cube technologies to see if such technology could provide a service that would integrate data from various sources (model and observational) in a central location where it would be easily accessible to researchers. We tested the feasibility for implementation of several open source data cubes -- Open Data Cube (ODC), rasdaman, and SciDB.
Beyond the simpler data cube concepts, the IDA programme recognised that a more advanced framework was required that could link large multi-resolution and multi-domain datasets together. These multi-resolution data cubes could enable the next generation of analytic processes to be developed. The Open Geospatial Consortium’s Discrete Global Grid System (DGGS) could be part of the solution (DGGS 2017). IDA supported co-authorship of the DGGS Specification – Topic 21 [OGC 15-104r5] (Purss & Gibb 2017). DGGS is a new type of spatial reference systems that uses a hierarchical sequence of equal area discrete global grids to model, partition and address the globe. One of its goals it to make it easy to integrate geospatial data from various sources seamlessly. The OGC DGGS will become a standard in the ISO 19100 series of geospatial standards. Organisations that are building (or have built) systems using the DGGS standard include UK Defence Science and Technology Laboratory, Google (S2), Uber (H3), GeoScience Australia, and Statistics Australia (AusPIX). The governments of Canada, Australia, China, and the UK are investing significantly in DGGS. The United Nations Global Geospatial Information Management (UN-GGIM) has recommended DGGS as a common global geography for sharing national statistics. This has interested New Zealand organisations like Statistics NZ and LINZ.
There is increasing demand for greater transparency of the science underpinning decision-making processes in natural resource management. Data provenance is information on how data were specifically derived (processes or transformations), including the source data (ancestral data products) from which the data item stems; basically, the what, when, where, who, how, which, and why of a data set. To illustrate how the application of data provenance increases the credibility and transferability of scientific methods and outputs, staff from IDA implemented automatic data provenance generation for two different land use-related environmental modelling frameworks based on the PROV family of standards (W3C 2013a): first, in the generation of land use classifications using ‘pyluc’, a python-based workflow tool; second, within the modelling environment of LUMASS, provenance information for New Zealand’s sediment budget model SedNetNZ is gathered and made available for archiving, querying, and visualisation by different users. In both cases, detailed provenance-tracking resulted in information that is complex and large. We therefore developed interactive visualisation tools for data provenance to help science producers and users explore, verify, and understand model outputs.
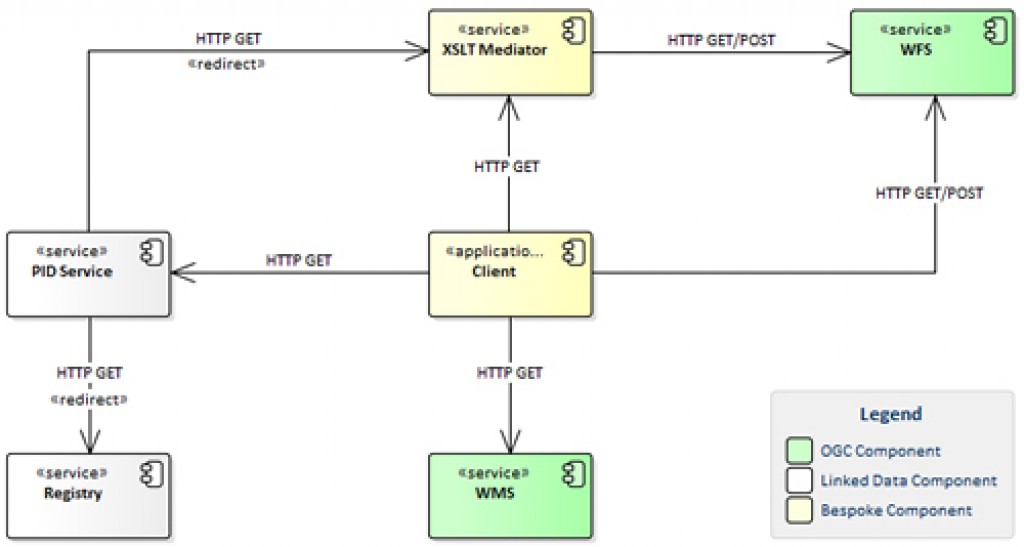
IDA looked at new ways to integrate and publish environmental data. IDA investigated and successfully set up a test data publication service using the forthcoming Open Geospatial Consortium WFS 3.0 specification. WFS 3.0 is the next version of the OGC Web Feature Service standard. It will be a modernised service that aligns with the current architecture of the Web, has a focus on improving the developer experience, and will likely be a blueprint for the next versions of other OGC service types. We looked at the use of Linked Data, common domain conceptual models, ontologies, e.g. SKOS, and vocabularies as a way to achieve cross-agency environmental data sharing and integration. We proved this concept by applying Linked Data API and OGC Web Feature Service API practices and semantics to the work undertaken in the OGC Environmental Linked Feature Interoperability Experiment (ELFIE) project (Blodgett et al. 2018). The concept was also demonstrated in the MfE e-IDI project to which IDA staff provided expert advice. Together, the results showed one way by which environmental data from Manaaki Whenua and other NZ data providers could be formally described, shared, and integrated. Through our work and engagement, such as hosting an Environmental Data Summit during the Open Geospatial Consortium (OGC) Technical and Planning Committee meeting that took place in Palmerston North in December 2017, IDA increased awareness in New Zealand about the fundamental needs for robust data-management principles and optimal design of components of environmental data infrastructures.
The final piece of work in this component involved summarising key aspects of the IDA programme in a more technical document and bringing together the knowledge gained to describe the technical details of the implementation of a multi-indicator environmental data infrastructure. The international standards work that IDA undertook with different international agencies, such as the Open Geospatial Consortium, CSIRO, and ISRIC (the World Soils Data Centre), helped the evolution of the design and implementation. To test the viability of the proposed architecture, a simple proof of concept (POC) was implemented where data from soil quality and land use were used to create a Soil Quality Assessment Tool. The resulting POC can be extended and reused to generate indicators associating land-use and soil-quality databases in line with international standards. The POC showed that adopting technical standards and international best practices across domains and agencies is critical: it reduces the risk we will reinvent the wheel and we can also build on the lessons gained by overseas institutions. The work also highlighted the importance of social architecture for the successful implementation of complex environmental information systems and infrastructures.